Fine-Tuning vs RAG
Two paths to customizing AI for your domain. Understanding the tradeoffs is essential for building effective AI systems.
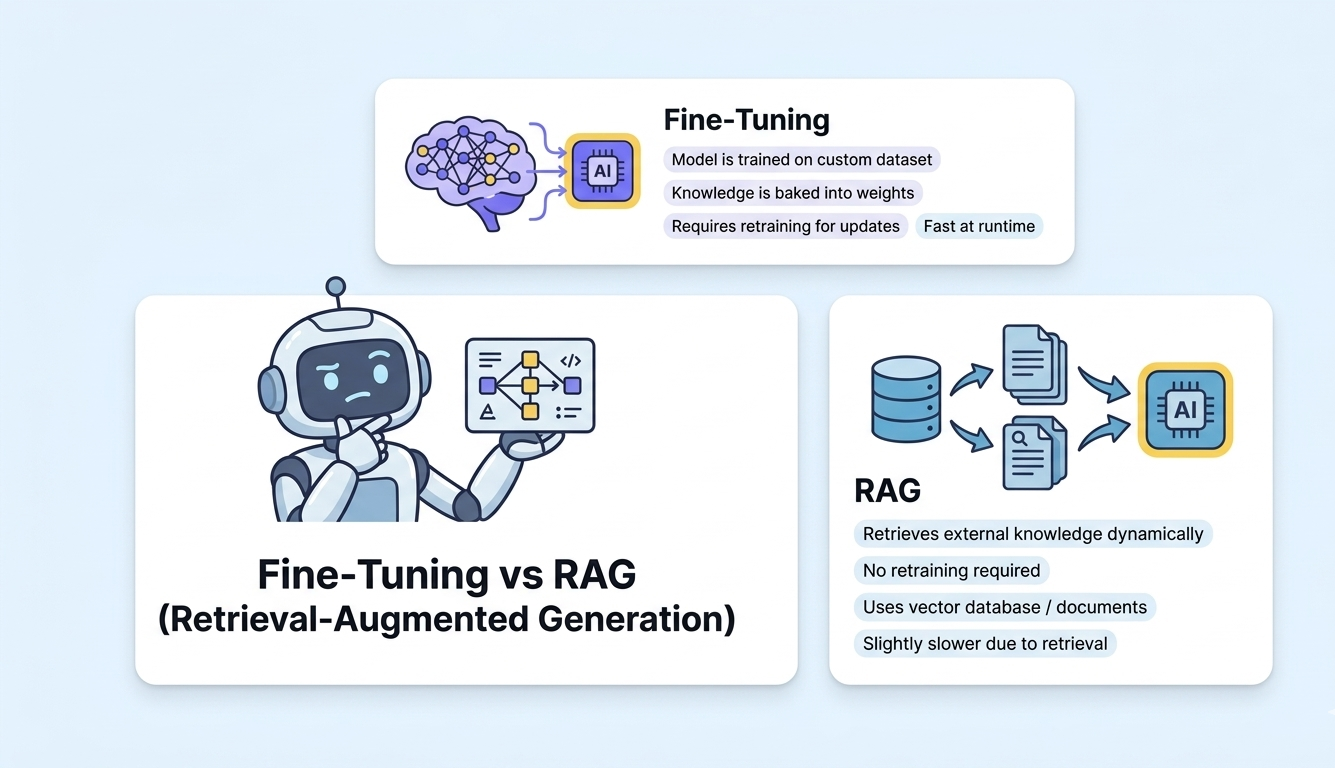
When a general-purpose LLM does not meet your needs, you have two primary strategies for customization: fine-tuning the model on your data, or using Retrieval-Augmented Generation (RAG) to provide context at query time. Fine-tuning modifies the model weights to embed domain knowledge permanently. RAG keeps the model unchanged but feeds it relevant documents for each query. Both have distinct advantages, costs, and failure modes that every AI team must understand.
TL;DR
Start with RAG — it is faster to implement, easier to update, and works well for most knowledge-grounding use cases. Use fine-tuning when you need to change the model behavior, tone, or output format, or when your domain requires knowledge that is difficult to retrieve. Combining both approaches often yields the best results.
Overview
Fine-Tuning
Training an LLM on your domain-specific dataset to modify its weights and behavior. Changes how the model generates responses, its style, format adherence, and domain knowledge.
RAG (Retrieval-Augmented Generation)
Retrieving relevant documents from a knowledge base and providing them as context to the LLM at query time. The model remains unchanged; knowledge comes from the retrieved documents.
Head-to-Head Comparison
How Fine-Tuning and RAG (Retrieval-Augmented Generation) stack up across key criteria.
| Criteria | Fine-Tuning | RAG (Retrieval-Augmented Generation) |
|---|---|---|
| Implementation Speed | Requires dataset preparation, training, and evaluation — weeks to months | Winner Index documents and start querying — days to weeks |
| Knowledge Freshness | Requires retraining to update knowledge; stale between cycles | Winner Update the knowledge base in real-time; always current |
| Behavioral Customization | Winner Can deeply modify tone, format, reasoning style, and domain behavior | Limited to prompt engineering for behavioral changes |
| Cost Efficiency | Training costs plus ongoing inference; cheaper inference per token | Winner No training costs; slightly higher inference costs from longer prompts |
| Hallucination Control | Fine-tuned models can still hallucinate on unfamiliar queries | Winner Grounded in retrieved documents with source attribution |
| Data Requirements | Needs hundreds to thousands of high-quality training examples | Winner Works with unstructured documents, PDFs, and existing content |
| Scalability of Knowledge | Knowledge limited by model capacity and training data volume | Winner Scales to millions of documents in the vector database |
| Transparency & Explainability | Hard to trace why the model produced a specific answer | Winner Can cite exact source documents and passages used for each answer |
Implementation Speed
Requires dataset preparation, training, and evaluation — weeks to months
Index documents and start querying — days to weeks
Knowledge Freshness
Requires retraining to update knowledge; stale between cycles
Update the knowledge base in real-time; always current
Behavioral Customization
Can deeply modify tone, format, reasoning style, and domain behavior
Limited to prompt engineering for behavioral changes
Cost Efficiency
Training costs plus ongoing inference; cheaper inference per token
No training costs; slightly higher inference costs from longer prompts
Hallucination Control
Fine-tuned models can still hallucinate on unfamiliar queries
Grounded in retrieved documents with source attribution
Data Requirements
Needs hundreds to thousands of high-quality training examples
Works with unstructured documents, PDFs, and existing content
Scalability of Knowledge
Knowledge limited by model capacity and training data volume
Scales to millions of documents in the vector database
Transparency & Explainability
Hard to trace why the model produced a specific answer
Can cite exact source documents and passages used for each answer
When to Use Each
Use Fine-Tuning when...
- You need the model to adopt a specific tone, style, or output format consistently
- Domain-specific reasoning or terminology must be deeply embedded
- You want faster inference without long context windows
- Your use case requires specialized classification or structured output
- You have a clean, large dataset of examples in the target domain
Use RAG (Retrieval-Augmented Generation) when...
- Your knowledge base changes frequently and must be up-to-date
- You need source attribution and explainability for answers
- You want to get to production quickly with minimal ML expertise
- Your data is in existing documents, PDFs, or knowledge bases
- Reducing hallucinations through grounding is a priority
Our Recommendation
We recommend starting every project with RAG. It is lower risk, faster to deploy, and easier to iterate. Layer fine-tuning on top when RAG alone does not achieve the desired output quality, behavioral consistency, or domain expertise. The combination of a fine-tuned model with RAG retrieval often produces the best results. WebbyButter can implement both strategies and help you find the optimal balance.
Master Custom AI Knowledge Grounding
Choosing between fine-tuning and RAG depends on your data freshness and behavior requirements. We help you find the right balance.
High-precision RAG implementation with advanced retrieval techniques. Custom model fine-tuning for specific tone, format, and reasoning. Hybrid architectures that combine model weights with live data.
Frequently Asked Questions
Explore More
Related Resources
rag-systems for healthcare
Purpose-built rag systems solutions designed for the unique challenges of healthcare. We combine deep healthcare domain ...
Learn moreai-chatbots for healthcare
Purpose-built ai chatbots solutions designed for the unique challenges of healthcare. We combine deep healthcare domain ...
Learn moreAI Project Cost Calculator
Get a realistic estimate for your AI project based on type, complexity, team size, and timeline. No guesswork — just dat...
Learn moreCustomize AI for Your Domain
Whether RAG, fine-tuning, or both, our AI engineers will implement the right customization strategy for your specific data and requirements.